日志监控简介
本章节的日志监控系统是基于ELKF架构来搭建的,下面将对ELKF架构进行简要的介绍以及为何要采用该种架构来构建日志监控系统。
ELKF简介
ELKF是Elasticsearch+Logstash+Kibana+Filebeat的简称。
Elasticsearch是一个开源的分布式搜索和分析引擎,可以用于全文检索、结构化检索和分析,它构建在Lucene搜索引擎库之上,是当前使用较为广泛的开源搜索引擎之一。
Logstash是一个开源的数据搜集引擎是一个用来搜集、分析、过滤日志的工具,使用它可以将搜集来的日志信息进行处理然后进行输出。Logstash支持许多功能强大的插件,可以合理使用这些插件来对搜集到 的日志信息进行过滤和处理。
Kibana是一个基于Web的图形界面,可以使用它对Elasticsearch索引中的数据进行搜索、查看、交互操作。还可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Filebeat是一个轻量级的日志搜集器,用于搜集和转发日志数据,Filebeat一般都会安装在需要搜集日志的服务器上,指定需要搜集日志的日志文件的位置,搜集日志信息并转发到Elasticsearch 或Logstash上进行索引。
ELKF架构
ELKF日志监控平台架构图如下:
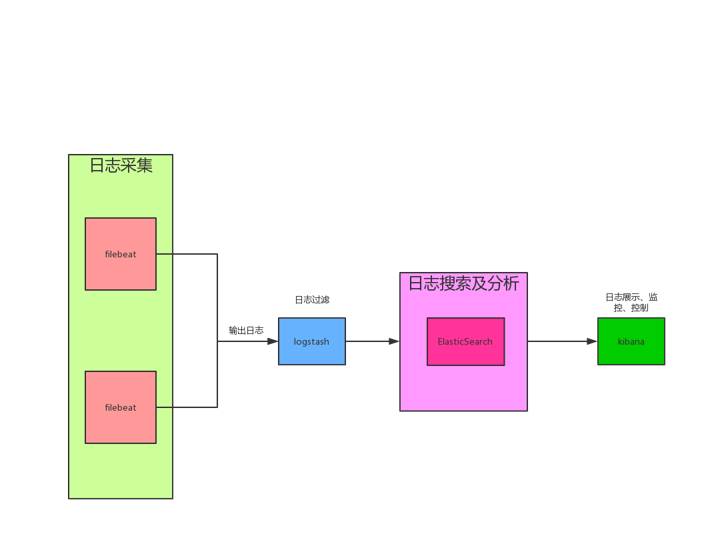
其中, Filebeat 主要用于在服务器中采集服务日志信息并输出到 Logstash, Logstash 负责接收所有 Filebeat 传递过来的日志数据,并对数据进行过滤筛选处理后输出到 Elasticsearch, Elasticsearch 主要用于日志消息的存储,搜索和分析,在 Elasticsearch 中存储的索引信息最终会通过 Kibana 在页面上直观的进行展示。最终用户可以在 Kibana 页面中操作索引,查询日志, 监控 Elasticsearch 和 Kibana 的健康状态,以及配置多种 Dashboard 来展示聚合数据信息。
总结来说,ELKF 日志监控大体上分为两部分,Elasticsearch、Logstash 和 Filebeat 负责数据的搜集,过滤,存储和分析,Kibana 负责操作存储在 Elasticsearch 中的索引信息,监控 Elasticsearch 和 Kibana 的健康状态以及管理用户信息。 同时用户还可以配置多种 Dashboard 来展示数据聚合信息。
为什么采用ELKF架构
1.Elasticsearch、Logstash、Kibana、Filebeat 均为开源组件,并且使用 ELKF 搭建日志监控系统的方案也比较成熟。
2.一般的日志监控系统架构都是采用 ELK(Elasticsearch、Logstash、Kibana)架构去搭建的,但是由于 Logstash 本身是基于 jdk 的,且它集成了许多插件,所以占用内存较大,在每台服务器上都部署一 个 Logstash 有些占用资源,因此我们使用轻量级的 Filebeat 组件来完成搜集日志的操作。但是 Filebeat 只能采集日志数据却无法对数据进行过滤,因此我们在将日志信息输出到 Elasticsearch 之前先使 用 Logstash 对数据进行过滤处理,再将处理好的数据输出到 Elasticsearch。
3.在微服务场景下,可能存在如下两种情况:
(1)开发或生产环境的微服务项目部署在多台服务器上,此时需要监控多台服务器下的日志信息情况;
(2)一台服务器下既存在开发环境的微服务项目,又存在生产环境的微服务项目,此时需要将搜集到的日志信息加以区分。
这种情况下我们可以在 Filebeat 采集日志时为日志信息指定每个不同环境的唯一前缀后再输出。例如:采集融合开发环境的日志时,我们可以在 Filebeat 中进行配置,将采集到的日志添加统一的前缀 (integration_dev-服务名称)加以区分。这样我们可以针对不同的环境,在采集日志输出之前都为其添加唯一的前缀,最终在 Kibana 中使用我们配置的唯一前缀(integration_dev-*)来创建索引模式来获取我们所需环境的日志信息。 而在这种场景下,使用 FileBeat 就要比使用 Logstash 更加节约资源了。