服务地址
功能说明

Groovy脚本:基于表导出Liquibase Groovy脚本,支持批量导出
数据库对比:对比不同环境中数据库差异,生成xml脚本文件
数据导出:使用XML模板文件导出数据到Excel文件,支持批量导出和全量导出
差异化数据导出:使用XML模板文件和本地Excel文件数据对比导出新增/删除的数据到Excel文件,支持批量导出和全量导出
数据导入:基于Liquibase Groovy脚本更新数据库,导入Excel文件,支持批量导入
Groovy脚本导出
- 进入Groovy脚本菜单填写信息并生成脚本
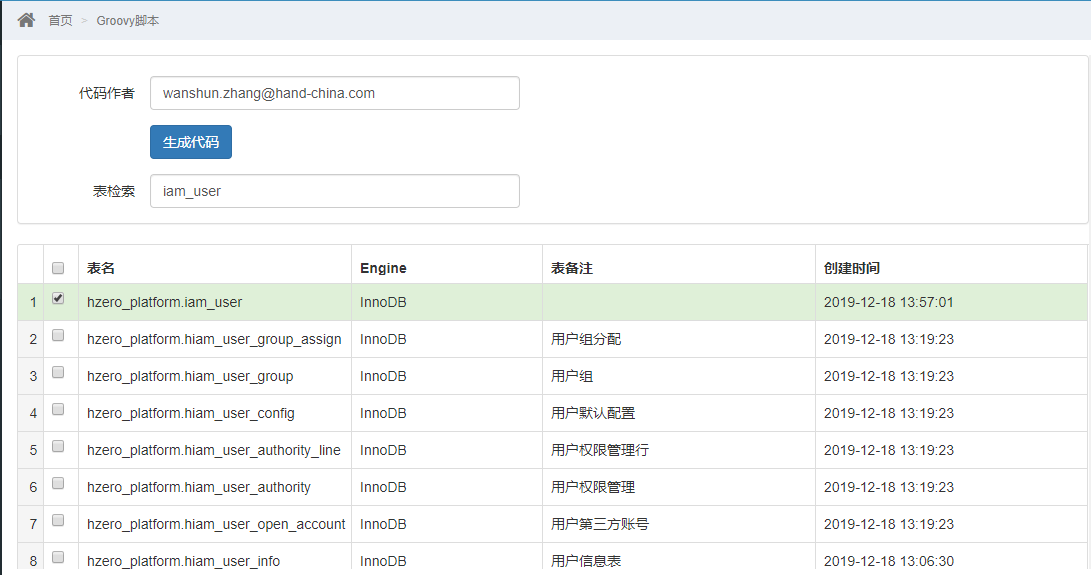
-
下载生成脚本
-
查看生成脚本
-
确认无误后,拷贝到项目
src下即可
数据库对比
- 进入数据库对比菜单填写信息并生成代码
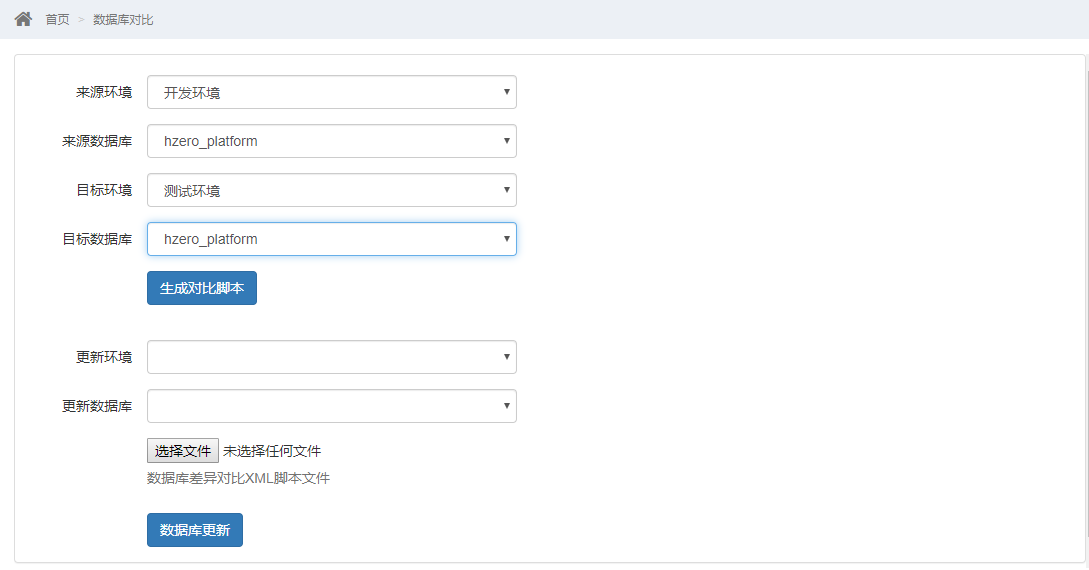

生成的数据库对比脚本仅供参考
- 选择需要更新的环境和数据库,确认xml脚本文件无误,导入文件点击数据库更新按钮
数据导出
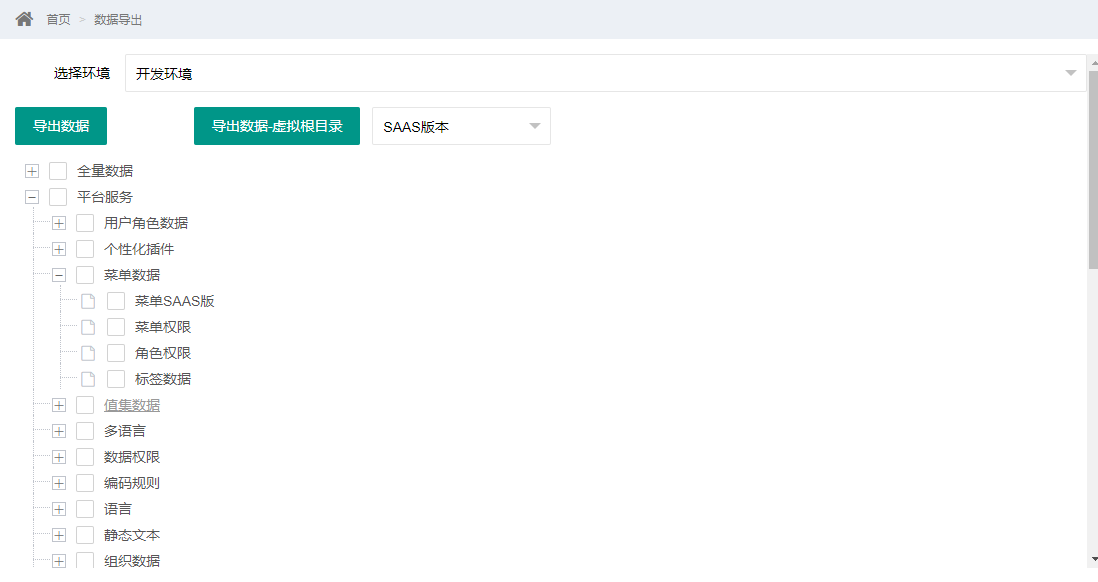
- 在application.yml中修改数据源配置,只需修改IP、端口、用户名、密码即可,支持四个环境页面随意切换
datasource:
# 开发环境
dev:
driver-class-name: com.mysql.jdbc.Driver
url: ${SPRING_DATASOURCE_URL:jdbc:mysql://dev.hzero.org:3306?useUnicode=true&useSSL=false}
username: ${SPRING_DATASOURCE_USERNAME:hzero}
password: ${SPRING_DATASOURCE_PASSWORD:hzero}
# 测试环境
tst:
driver-class-name: oracle.jdbc.driver.OracleDriver
url: ${SPRING_DATASOURCE_URL:jdbc:oracle:thin:@tst.hzero.org:1521:sid}
username: ${SPRING_DATASOURCE_USERNAME:hzero}
password: ${SPRING_DATASOURCE_PASSWORD:hzero}
# 验收环境
uat:
driver-class-name: com.microsoft.sqlserver.jdbc.SQLServerDriver
url: ${SPRING_DATASOURCE_URL:jdbc:sqlserver://uat.hzero.org:1433;}
username: ${SPRING_DATASOURCE_USERNAME:hzero}
password: ${SPRING_DATASOURCE_PASSWORD:hzero}
# 生产环境
prd:
driver-class-name: org.postgresql.Driver
url: ${SPRING_DATASOURCE_URL:jdbc:postgresql://prd.hzero.org:5432/postgres}
username: ${SPRING_DATASOURCE_USERNAME:hzero}
password: ${SPRING_DATASOURCE_PASSWORD:hzero}
1.基础数据导出
-
如果只需导出平台服务基础数据,上面的配置修改好后即可进行数据导出
-
页面选择环境,选择数据版本,勾选需要导出的数据条目,点击导出数据按钮,即可生成Excel打包下载到本地
-
导出的文件按服务分类,服务下面包含此服务用到的其它服务
-
虚拟根目录导出,用于系统升级后菜单初始化,将在平台基础菜单目录结构之上添加一个虚拟顶层菜单,避免客制化的菜单数据被覆盖
如果平台版本比较低,存在数据库结构不对应导出报错,可根据情况调整resources\xml\services目录下模板文件,同客制化数据导出介绍
2.客制化数据导出
- 如果提供的导出模板不符合需求,可自行调整模板,导出需要的数据
- 自定义模板介绍:
<?xml version="1.0" encoding="UTF-8"?>
<!--name:服务名,order:排序,description:描述-->
<service name="" order="" description="">
<!--name:模块名称,description:描述,fileName:文件名,schema:数据库-->
<excel name="" description="" fileName="" schema="">
<!--name:名称,description:页面显示名称和Excel页名称-->
<sheet name="" description="">
<!--name:表名,description:描述-->
<table name="" description="">
<!--sql语句,包含需要查询的字段和where条件,主表别名为 t -->
<sql>SELECT ...
FROM ...
WHERE 1=1
</sql>
<!--主键,默认自增,保持原ID只需加个*号,例如 <id>*tenant_id</id> -->
<id></id>
<!--引用字段,主键是否被其它表引用-->
<cited></cited>
<!--唯一性索引,多个用逗号分隔-->
<unique></unique>
<!--多语言(可配多个),field:多语言列,pkName:关联主键-->
<lang>
<field></field>
<pkName></pkName>
</lang>
<!--类型(可配多个),field:类型列,type:类型-->
<type>
<field></field>
<type></type>
</type>
<!--关联(可配多个),field:关联列,sheetName:关联的sheet,tableName:关联的表,columnName:关联的列-->
<reference>
<field></field>
<sheetName></sheetName>
<tableName></tableName>
<columnName></columnName>
</reference>
</table>
</sheet>
</excel>
</service>
-
在数据库管理工具中编写sql美化后粘贴到sql标签中即可,导出字段按sql中字段的顺序用逗号切分所得
-
cited、lang、type、reference等标签如果不需要可去掉,其它标签为必须,同一个sheet标签内表关联sheetName标签可省略
-
xml中包含一个service,service可包含多个excel,excel可包含多个sheet,sheet可包含多个table,table包含sql、id、cited、unique、lang、type、reference等标签
-
在resources\xml\services\template目录下有空白模板和demo模板,copy一份修改为自己的内容,放到services目录下,在xml\mapping\service-mapping.xml添加自定义的服务映射
举个栗子:
- 以导出 [平台服务-值集数据] 为例,首先在resources\xml\services下建一个hzero-platform.xml文件(copy一份template中的模板过来改)
- 修改服务名、排序和描述,修改excel标签的名称、描述、生成的excel文件名和使用的数据库
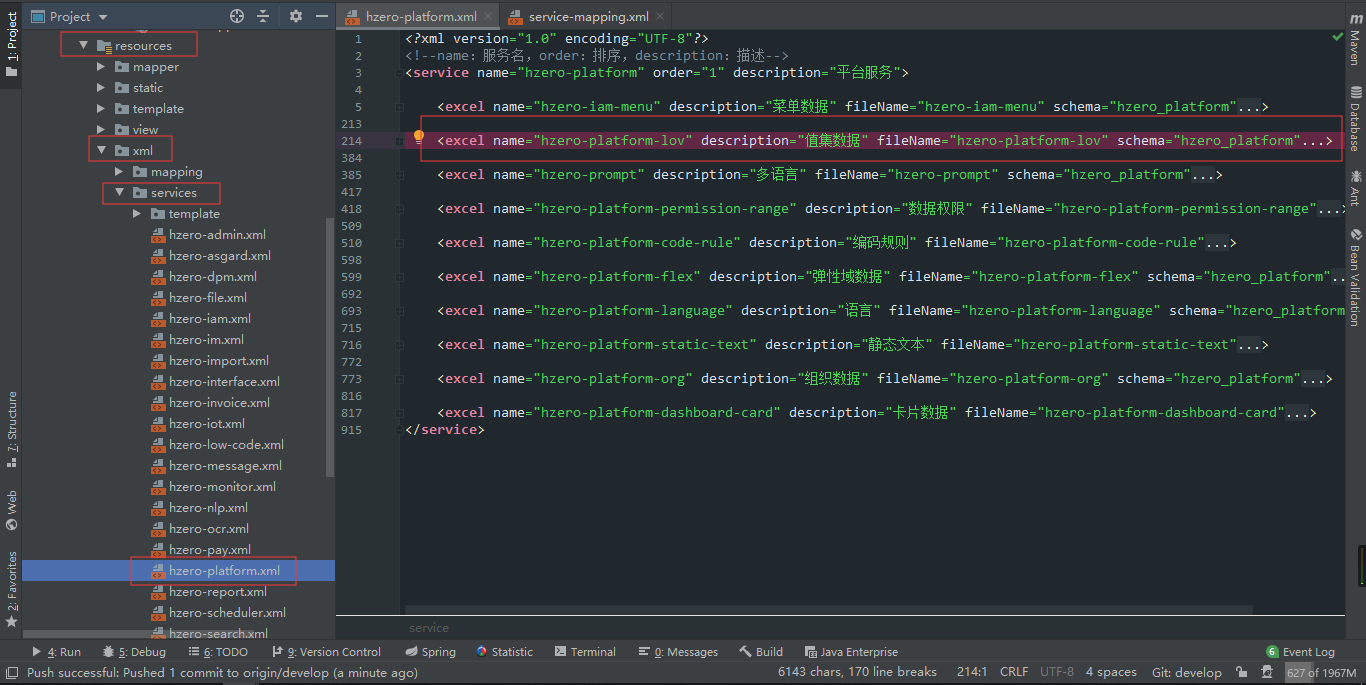
- 修改sheet标签名称和描述,这里excel中只包含了一个sheet(可包含多个),sheet中包含了值集的四张表,table的name属性为表名

- hpfm_lov表内容如下
<table name="hpfm_lov" description="LOV表">
<sql>SELECT
lov_id,
lov_code,
lov_type_code,
route_name,
lov_name,
description,
tenant_id,
parent_lov_code,
parent_tenant_id,
custom_sql,
custom_url,
value_field,
display_field,
must_page_flag,
enabled_flag,
translation_sql
FROM
hpfm_lov
WHERE
enabled_flag = 1
AND tenant_id = 0
AND (
lov_code LIKE 'HPFM.%'
OR lov_code LIKE 'HIAM.%'
OR lov_code LIKE 'HOTH.%'
OR lov_code LIKE 'HADM.%'
)
</sql>
<id>lov_id</id>
<cited>lov_id</cited>
<unique>lov_code,tenant_id</unique>
<lang>
<field>lov_name</field>
<pkName>lov_id</pkName>
</lang>
<lang>
<field>description</field>
<pkName>lov_id</pkName>
</lang>
</table>
- 在数据库管理工具中编写SQL查询出自己需要的内容,美化后粘贴到
<sql>标签中,where条件中如果有关联查询用到了主表,别名为 t - hpfm_lov表主键为lov_id且自增,在
<id>标签中标注且不带 * 号 - hpfm_lov表被后续表关联,关联字段为lov_id,在
<cited>标签中标注 - lov_code,tenant_id为唯一性索引字段,在
<unique>标签中标注 - lov_name,description为多语言字段,在
<lang>标签中标注,<field>为列字段,<pkName>为主键 - hpfm_lov_value表内容如下
<table name="hpfm_lov_value" description="LOV独立值集表">
<sql>SELECT
lov_value_id,
lov_id,
lov_code,
value,
meaning,
description,
tenant_id,
tag,
order_seq,
parent_value,
start_date_active,
end_date_active,
enabled_flag
FROM
hpfm_lov_value
WHERE
enabled_flag = 1
AND tenant_id = 0
AND (
lov_code LIKE 'HPFM.%'
OR lov_code LIKE 'HIAM.%'
OR lov_code LIKE 'HOTH.%'
OR lov_code LIKE 'HADM.%')
</sql>
<id>lov_value_id</id>
<unique>lov_id,value,tenant_id,parent_value</unique>
<lang>
<field>meaning</field>
<pkName>lov_value_id</pkName>
</lang>
<lang>
<field>description</field>
<pkName>lov_value_id</pkName>
</lang>
<type>
<field>start_date_active</field>
<type>DATE</type>
</type>
<type>
<field>end_date_active</field>
<type>DATE</type>
</type>
<reference>
<field>lov_id</field>
<tableName>hpfm_lov</tableName>
<columnName>lov_id</columnName>
</reference>
</table>
- hpfm_lov_value表与hpfm_lov表不同点:没有了
<cited>标签,增加<type>标签和<reference>标签 - hpfm_lov_value表没有被其它表引用,所以不需要
<cited>标签,start_date_active/end_date_active为时间类型,使用使用<type>标签,lov_id字段关联了hpfm_lov表的主键,所以使用了<reference>标签 <reference>标签中field为关联的列,tableName为关联的表,columnName为被关联表的列,这里两张表都在同一个sheet标签中,所以省略了<sheetName>标签,如果使用则为关联sheet的name属性(如:<sheetName>lov</sheetName>)- hpfm_lov_view_header表内容如下
<table name="hpfm_lov_view_header" description="值集查询视图头表">
<sql>SELECT
view_header_id,
view_code,
view_name,
lov_id,
tenant_id,
value_field,
display_field,
title,
width,
height,
page_size,
delay_load_flag,
children_field_name,
enabled_flag
FROM
hpfm_lov_view_header
WHERE
enabled_flag = 1
AND tenant_id = 0
AND (
view_code LIKE 'HPFM.%'
OR view_code LIKE 'HIAM.%'
OR view_code LIKE 'HOTH.%'
OR view_code LIKE 'HADM.%'
)
</sql>
<id>view_header_id</id>
<cited>view_header_id</cited>
<unique>view_code,tenant_id</unique>
<lang>
<field>view_name</field>
<pkName>view_header_id</pkName>
</lang>
<lang>
<field>title</field>
<pkName>view_header_id</pkName>
</lang>
<reference>
<field>lov_id</field>
<tableName>hpfm_lov</tableName>
<columnName>lov_id</columnName>
</reference>
</table>
- hpfm_lov_view_header表关联了hpfm_lov表,且主键自增被后续行表关联,所以
<id>和<cited>标签都有 - hpfm_lov_view_lineb表内容如下
<table name="hpfm_lov_view_line" description="值集查询视图行表">
<sql>SELECT
view_line_id,
view_header_id,
tenant_id,
lov_id,
display,
order_seq,
field_name,
query_field_flag,
table_field_flag,
table_field_width,
enabled_flag
FROM
hpfm_lov_view_line
WHERE
enabled_flag = 1
AND tenant_id =0
</sql>
<id>view_line_id</id>
<unique>view_header_id,field_name</unique>
<lang>
<field>display</field>
<pkName>view_line_id</pkName>
</lang>
<reference>
<field>view_header_id</field>
<tableName>hpfm_lov_view_header</tableName>
<columnName>view_header_id</columnName>
</reference>
<reference>
<field>lov_id</field>
<tableName>hpfm_lov</tableName>
<columnName>lov_id</columnName>
</reference>
</table>
- hpfm_lov_view_line表不同的是关联了两张表,hpfm_lov_view_header和hpfm_lov
- 以此类推,定义好需要导出的数据模板,最后在在resources\xml\mapping\service-mapping.xml中加上自己的服务映射
- 如果不想页面显示过多自己不需要的列表,可在org.hzero.generator.util.XmlUtils.java中加入不需要的模板文件
class XmlUtils{
/**
* 需要过滤掉的文件
*/
private static List<String> SKIP_FILE = new ArrayList<>();
static {
// 忽略模板文件
SKIP_FILE.add("template-vacancy.xml");
SKIP_FILE.add("template-demo.xml");
}
}
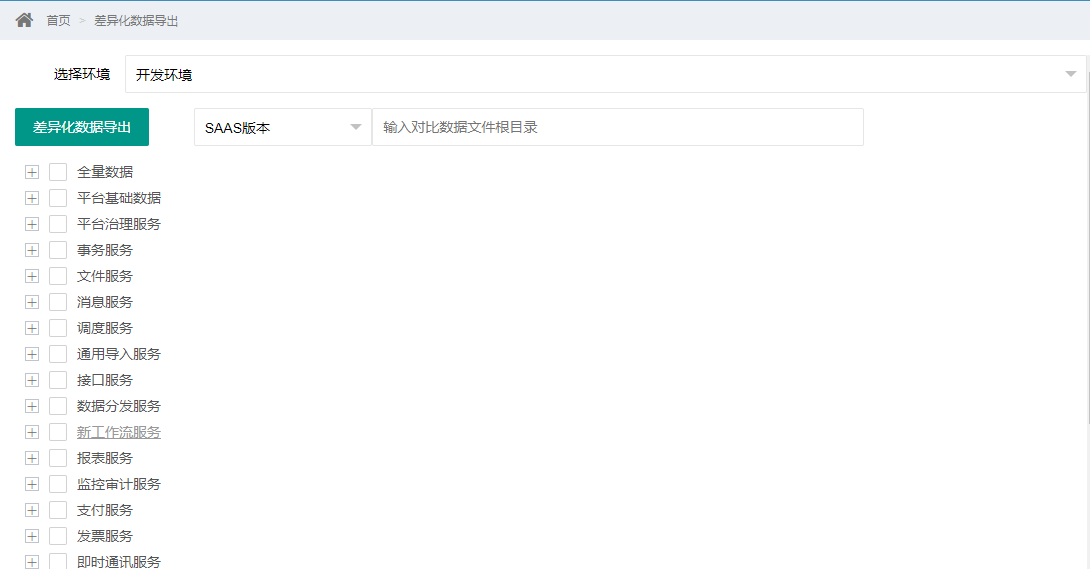
差异化数据导出
-
差异化数据导出与上面的数据导出操作类似,也是根据需要修改xml文件中的内容,调整好之后将本地存储的Excel数据文件根路径填入到输入框中
-
选择环境和菜单版本,勾选需要导出的模块即可导出差异化数据,Excel文件分别以
-append和-delete结尾 -
导出的数据可直接使用导入工具导入,新增的数据会插入,删除的数据会进行删除
补充说明:差异化是指数据库与本地Excel中的数据的差异
数据导入
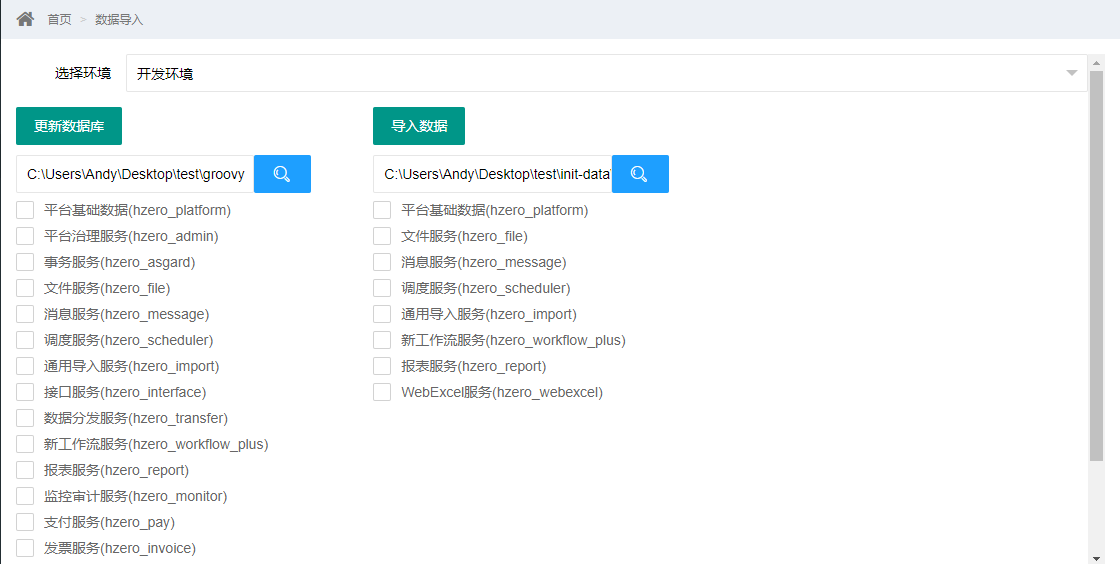
更新数据库
-
数据导入之前先确认数据库已初始化好
-
将groovy脚本根目录粘贴到输入框中,点击按钮获取脚本服务列表
-
选择更新的环境,选中需要更新的服务,点击更新数据库
导入数据
- 将导出工具导出的压缩包解压到本地,目录结构如下

-
将数据目录根目录填写到输入框中,点击查询按钮,获取可导入的服务列表
-
选择更新的环境,选中需要导入的数据,点击导入数据